
The Apache Modeling Project. Глава 2 (Часть 2)
Предыдущая статья: The Apache Modeling Project. Глава 2 (Часть 1)
Виртуальные хосты
Виртуальные хосты - это концепция, позволяющая нескольким логическим веб-серверам располагаться на одном физическом сервере (даже с одним IP адресом). Вот несколько реализаций этой концепции:
- Физический сервер связан с множеством IP адресов, и каждый IP адрес используется одним логическим сервером.
- Физический сервер связан с одним IP адресом, а логические серверы используют разные порты. В URL это выглядит так: /go.php?url=http://www.xyz.com:81/.
- Физический сервер связан с одним IP адресом. Несколько доменных имен связываются с этим IP адресом. Все логические веб-сервера прослушивают один единственный порт. Сервер различает запросы, используя поле HOST, которое является обязательным в HTTP запросах в HTTP версии 1.1.
HTTP/1.0 явно не поддерживал виртуальные хосты. Веб-сервер, управляющий множеством доменов, различал запросы по IP адресу назначения (п.1) или по порту (п.2). Так как различные порты редко использовались для виртуальных хостов, то серверу необходим был для каждого домена отдельный IP адрес. Когда Интернет начал стремительно расти, количество свободных IP адресов стало резко сокращаться. Решение, основанное на разных портах, было неудобным и могло вызвать путаницу, если пользователь забудет указать номер порта.
В HTTP/1.1 было введено новое поле HOST, которое стало обязательным для каждого HTTP запроса. И сейчас сервер может обслуживать множество доменов по одному IP адресу и порту, различая назначения запроса, используя поле HOST.
Выбор контента на стороне сервера
У разных пользователей наилучшим образом отображаются разные версии одного документа. Apache может хранить несколько версий одного документа: либо на различных языках, либо в разных форматах. Так, например, стандартная страница, отображаемая после того, как Apache был успешно установлен, является примером документа с множеством версий, каждая на разном языке. Есть два способа определения лучшей версии для пользователя: серверный выбор и клиентский выбор контента.
Серверный выбор контента. В этом случае сервер решает, какую версию запрошенного документа следует отправить клиенту. Используя заголовок Accept, клиент может предоставить серверу список поддерживаемых форматов и языков. Проанализировав этот список, сервер попытается выбрать наиболее подходящую версию.
Клиентский выбор контента. В предыдущем методе не определено поведение в ситуации, когда ни одна из запрошенных версий не существует на сервере. Так как передача списка всех поддерживаемых форматов в желаемом порядке нереальна, то клиент может использовать заголовок Accept со значением Negotiate. В этом случае сервер вернет список доступных версий документа вместо самого документа. И при следующем запросе клиент может напрямую запросить выбранную версию.
Устойчивые соединения
HTTP версии 1.0 ограничивался лишь одним TCP соединением для каждого запроса. Во времена разработки HTTP, HTML документы обычно состояли только из одного файла, поэтому такой протокол был вполне достаточен. С тех пор отдельные веб-страницы выросли до мультимедийных сайтов. И теперь одна страница стала состоять из множества файлов. Теперь страницы содержат: изображения, звуки, анимацию и прочее. Так, например, главная страница популярного новостного сайта сегодня нуждается примерно в 150 различных файлах. А открытие и закрытие TCP соединения для каждого файла создает дополнительную задержку и увеличивает нагрузку на сервер. Поэтому разработчики вскоре добавили в заголовок поле “Connection: keep-alive” для возможности повторного использования TCP соединения, не смотря на то, что он не являлся частью стандарта HTTP.
Поэтому в HTTP/1.1 было официально введено понятие устойчивого соединения и поле Connection. Сейчас по умолчанию соединение является устойчивым. Когда один из корреспондентов не желает использовать соединение дальше, он устанавливает значение “Сonnection: close” для уведомления, что соединение будет закрыто после того, как выполнится текущий запрос. Apache предоставляет две директивы конфигурации: для ограничения количества запросов в одном соединении и для задания таймаута, после которого соединение закроется, если дальнейшие запросы перестанут приходить.
Прокси и кеш
По статистике известно, что большой процент используемого трафика состоит из небольшого числа HTML документов. Также известно, что большинство из этих документов не меняется со временем. Кеширование - это технология, применяемая для временного сохранения копий запрошенных документов либо на стороне клиентских приложений, либо на прокси-серверах, находящихся между клиентом и сервером.
Прокси-сервера. Прокси-сервер - это хост, играющий роль передающего агента для HTTP запроса. Клиент, сконфигурированный на использование прокси-сервера, никогда не запросит документы у веб-сервера напрямую. С каждым запросом он открывает соединение с указанным прокси-сервером и запрашивает у него либо доставить документ. Если прокси-сервер не имеет запрошенного документа, то он отправляет запрос далее. Количество прокси-серверов не ограничено одним на запрос. Следовательно, прокси-сервер может быть сконфигурирован на использование другого прокси-сервера. Технология использования нескольких прокси-серверов называется ‘каскадом серверов’. Прокси-сервера используются по двум причинам:
- Клиенты могут быть не в состоянии соединиться с веб-сервером напрямую. Часто прокси-сервера играют роль посреднического узла между приватной сетью и общедоступной сетью по соображениям безопасности. Клиент в приватной сети не имеет доступа к общедоступной сети, но он может запросить прокси-сервер перенаправить запросы в общедоступную сеть.
- Кеширующие прокси-сервера часто используются из-за соображений сохранения производительности и повышения пропускной способности сети. Документ, часто запрашиваемый несколькими узлами, запрашивается только один раз с сервера. Прокси-сервер может сохранить копию для ответа на следующие запросы на этот же документ без соединения с сервером.
Управление кешем. Хотя кеширование, безусловно, является хорошей технологией, она имеет свои проблемы. При кешировании документа необходимо определить, как долго этот документ будет пригодным для последующих запросов. Также некоторая информация является закрытой и не может кешироваться вовсе. Поэтому управление кешем является комплексной задачей, которая поддерживается протоколом HTTP с помощью различных полей заголовков. Наиболее важные из них:
If-modified-Since. Клиент может запросить документы по условию. Если клиент или прокси имеют копию документа, они могут запросить сервер прислать документ только в том случае, если он был изменен после указанной даты. Сервер возвращает документ, если он был изменен, или возвращает “304 Not Modified”, если изменений не было.
Expires. Используя это поле, сервер может назначать передаваемому документу время жизни. Клиент или прокси, способные кешировать и обрабатывать это поле, запросят заново этот документ только тогда, когда пройдет время, указанное в этом поле.
Last-Modified. Если сервер не может добавить время жизни документа, то клиенты или прокси могут использовать алгоритм, основанный на дате Last-Modified, полученной вместе с документом. HTTP/1.1 не указывает конкретных действий для обработки этой возможности. Клиенты и прокси могут быть сконфигурированы для использования этого поля на свое усмотрение.
Дополнительно HTTP/1.1 включает несколько полей заголовка для расширенного управления кешем. Серверы и клиенты могут запрашивать запрещенные для кеширования документы. Также серверы могут явно разрешать кеширование, а клиенты даже могут запрашивать документ у прокси-сервера, только в том случае, если это кешированная копия документа. Клиенты также могут информировать кеширующие прокси-сервера о том, что они готовы принять истекшие копии запрашиваемого документа.
2.4 Безопасность и управление доступом
2.4.1 Авторизация
Несмотря на то, что понятия авторизации и идентификации очень похожи, между ними существует большое различие. Идентификация - это процесс подтверждения той личности, за которую некто себя выдает, а авторизация означает проверку идентифицированного человека или машины на возможность получить доступ к некоторому ресурсу. HTTP сервер сперва проверяет, ограничен ли доступ к ресурсу. Если эти ограничения применяются к пользователям, тогда сервер запрашивает данные идентификации от клиента для проверки его прав. После этого сервер проверяет, разрешают ли правила авторизации доступ к ресурсу данному пользователю.
Доступ к ресурсу может быть ограничен для домена или адреса сети, для отдельного пользователя или для группы пользователей. Apache определяет эти ограничения, проверяя файлы конфигурации. Авторы также могут (при разрешении администратора) ограничивать доступ к своим документам через конфигурационные файлы .htaccess.
Правила авторизации применяются как для ресурсов, так для HTTP методов (например: запретить POST для неизвестных пользователей). Дополнительная информация об администрировании представлена в разделе 3.2.1.
2.4.2 Методы идентификации
Есть множество способов установки личности пользователя, который управляет браузером:
- Идентификатор пользователя (User ID) и пароль. Пользователь сообщает серверу свой ID и секретный пароль. Сервер проверяет их, используя базу пользователей. Если они совпадают, то пользователь идентифицирован успешно. База пользователей может быть разных видов:
- простой файл;
- база данных;
- механизм идентификации операционной системы или любого другого приложения;
- сервисы управления пользователями, такие как: LDAP, NIS, NTLM
- Цифровая подпись. Пользователь предоставляет сертификат, удостоверяющий его личность. Должны быть механизмы, чтобы убедиться, что только этот пользователь, и никто другой не может предоставить данный сертификат.
Есть два пути получения сервером данных идентификации:
- HTTP идентификация;
- HTML формы, java-апплеты и скрипты.
Получение данных идентификации с помощью HTTP
Когда запрос обращен к защищенному ресурсу, Apache отсылает следующий ответ клиенту: “401 unauthorized”. Это делается, чтобы информировать клиента о том, чтобы он добавил свои данные идентификации в следующий запрос. Вместе с 401 ответом сервер отсылает realm - значение, идентифицирующее запрошенный защищенный ресурс.
После этого браузер запрашивает данные идентификации у пользователя (имя и пароль). Далее клиент повторяет запрос, но уже с добавленными данными идентификации. Эти данные передаются через поля HTTP заголовков.
Так как протокол HTTP не запоминает состояния, то данные идентификации должны передаваться в каждом запросе. Браузер обычно хранит эту информацию в течение своей сессии. Для каждого запроса, обращенного к одному realm, браузер отсылает сохраненную информацию идентификации.
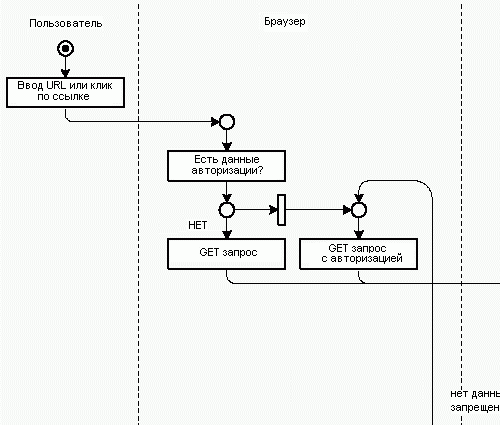
Как правило, для передачи данных идентификации используют HTTPS.
Базовая идентификация. Базовая идентификация - это самый простой метод идентификации. Хотя пароль может храниться в зашифрованном виде на сервере, браузер все равно передает имя пользователя и пароль в незашифрованном виде. Это означает, что имя пользователя и пароль может прочитать кто угодно. Запрошенный контент также отсылается без шифрования.
Решением этой проблемы может стать использование базовой идентификации вместе с шифрованием на TCP уровне - SSL. Использование SSL вместе с HTTP называется HTTPS. HTTPS гарантирует, что любая информация, отправляемая по сети, будет зашифрована. Подробнее об этом смотрите в 2.4.3.
Цифровая идентификация. Цифровая идентификация предоставляет альтернативный путь идентификации. Браузер отсылает серверу хэш-значение пароля в виде MD5-дайджеста. Однако данный метод уязвим для атаки “злоумышленник в середине”. Цифровая идентификация безопасней, чем базовая, но все-таки не обеспечивает полной безопасности. Необходимо использовать HTTPS. Для получения дополнительной информации по идентификации смотрите /go.php?url=http://httpd.apache.org/docs/howto/auth.html.
Получение данных идентификации с помощью HTML форм, Java-апплетов и Java скриптов
Браузеры обычно поддерживают базовую идентификацию. Другие методы требуют дополнительного программного обеспечения на стороне сервера. Существует еще несколько возможностей для обработки данных идентификации. Так, например, есть возможность вводить идентификационную информацию в HTML формы. Потом эта информация передается на сервер методом POST в теле запроса. Этим он отличается от базовой идентификации, где данные передаются в заголовках запроса. Затем CGI программа может произвести идентификацию. Другая возможность - это использовать java-апплеты и JavaScript. Сервер отсылает java-апплет или код JavaScript клиенту. Браузер выполняет этот код, который запрашивает данные идентификации и отсылает их серверу произвольным способом.
Оба метода требуют дополнительного программного обеспечения на сервере. Это может быть CGI скрипт, который обрабатывает содержание POST запросов. И в этом случае, для обеспечения безопасной передачи данных, необходимо использовать HTTPS.
2.4.3. HTTPS и SSL
Безопасность передачи данных означает невозможность получения её посторонними лицами. Как данные кредитной карточки, так и пароли, передаваемые через Интернет, нуждаются в обеспечении безопасности. Поэтому шифрование трафика стало такой важной задачей.
Идентификация объединила в себе технологии, которые позволяют быть уверенными в том, что взаимодействующие лица являются именно теми, за кого себя выдают. Это помогает предотвратить атаки типа “злоумышленник в середине”. Интернет-магазин или сайт банка должен идентифицировать себя, перед тем как запросить секретную информацию.
Безопасные соединения
Для безопасных соединений могут использоваться или симметричные алгоритмы, или алгоритмы, основанные на паре ключей (открытый и приватный). Используя симметричные алгоритмы, взаимодействующие лица нуждаются в одном ключе для шифрования и дешифрования информации. Это создает проблему, так как ключ необходимо передать от одного лица другому перед тем, как создается безопасное соединение. Безопасность передачи симметричного ключа обеспечивается использованием других механизмов безопасности.
Механизмы открытого/приватного ключа основаны на использовании двух разных ключей. Одно взаимодействующее лицо предоставляет свой открытый ключ всем желающим. Открытый ключ используется для шифрования сообщений, которые могут быть расшифрованы только владельцем приватного ключа. Использование этой технологии может обеспечить двустороннее безопасное соединение.
Механизмы, основанные на симметричных ключах, менее требовательны к ресурсам, чем механизмы, основанные на открытых/приватных ключах. Поэтому механизмы, основанные на парных ключах, часто используются для безопасной передачи симметричного ключа. Такая техника позволяет безопасно передать все данные и не сильно расходовать ресурсы.
Идентификация, основанная на сертификатах
Сертификатная идентификация основана на сертификатах, которые могут быть проверены на достоверность, используя сертификат специального центра. При запросе личности корреспондент предъявляет сертификат, который может быть проверен, используя сертификат центр. Данная проверка гарантирует достоверность результатов идентификации. Тем не менее, также необходимо быть уверенным в самом сертификационном центре. Поэтому существует несколько компаний, которые являются главными центрами сертификации, и у любого клиента есть список этих организаций. Остальные же центры сертификации получают свои сертификаты от основных центров.
Для уверенности, что сертификат не утерян, вместе с сертификатами используют механизмы, основанные на парных ключах. Владелец сертификата предоставляет текст, зашифрованный приватным ключом, который есть только у владельца. Центр сертификации хранит сертификат, содержащий открытый ключ, но не имеет понятие о приватном ключе. Однако полученный текст можно расшифровать, используя открытый ключ сертификата. Следовательно, если лицо, потребовавшее сертификат может зашифровать этот текст, значит, он является владельцем закрытого ключа и, следовательно, может получить требуемое. Для идентификации веб-серверов сертификат также содержит доменное имя. Сервер может быть идентифицирован, если он доступен только через то доменное имя, которое указано в сертификате.
HTTP и SSL
Протокол SSL может быть использован вместе с любым протоколом, таким как протокол TCP. Он обеспечивает работу механизмов безопасности и идентификации. SSL использует механизм парных ключей для обмена симметричными ключами сессий, которые используются для шифрования передаваемых данных. Сертификаты используются для идентификации. Вместе HTTP и SSL обычно называют безопасным HTTP или HTTPS. По умолчанию используется порт 443 вместо стандартного 80 порта. Браузеры показывают пользователям, что установлено безопасное соединение, а также предупреждают их, в случае если у сертификата истек срок или произошла иная ситуация, из-за которой безопасное соединение не может быть установлено.
HTTPS использует сертификаты для предоставления и проверки открытого ключа, который используется для обмена симметричным ключом. Таким образом, при установке связи с помощью HTTPS, клиент сначала запрашивает сертификат сервера, проверяет его на соответствие в сертификационном центре, и использует содержащийся открытый ключ для проверки “личности” сервера. Ключ также используется для обмена “вспомогательным секретным ключом”, который нужен для создания симметричного ключа, называемого также “основным ключом”. После этого каждый участник процесса передачи информации информирует другого, что дальнейшая передача будет шифрованная, и начинается HTTPS сессия.
HTTPS соединения могут быть заново использованы в течение определенного времени для уменьшения расходов на проверку идентификации и создания соединений.
SSL и Internet
Сегодня SSL используется почти во всех веб-приложениях, которые касаются платежей или секретной информации. Почти любой сайт электронной коммерции или банковская система, работающая на HTTP, используют SSL для обеспечения безопасности соединения.
SSL может быть использован для защиты любого протокола, использующего TCP. Установка связи с помощью SSL требует дополнительных действий от клиента и сервера, поэтому установление SSL соединения не может пройти незаметно для приложения. Решением является дублирование портов сервера, помещая TCP соединение внутри SSL соединения.
Несмотря на то, что SSL также поддерживает идентификацию клиента, она используется редко, так как требует наличия у клиента сертификата. Клиентский сертификат, требуемый для точной идентификации, покупается в сертификационном комитете. Так как компании хотят заставить своих покупателей платить только за покупки, обычно используются методы идентификации клиентов с помощью имени пользователя и пароля. При этом передача имени пользователя и пароля обычно зашифровывается с помощью SSL.
2.5 Управление сессиями
2.5.1 HTTP - протокол, не хранящий информацию о сессии
HTTP - протокол, который не хранит информацию о сессии. Это значит, что каждый HTTP запрос можно рассматривать как новый запрос, не связанный с предыдущими запросами. Серверы не сохраняют данные по предыдущим запросам клиента или данные сессии. Преимуществом данной модели является отсутствие необходимости хранения данных сессии. Это обеспечивает простую и быструю работу серверов. Для реализации более сложных клиент - серверных приложений, которым необходимы данные сессии, при каждом запросе клиент должен посылать на сервер хотя бы идентификатор сессии.
2.5.2 Хранение сессии
Если серверное приложение, например, программа CGI, должна работать с данными сессии, то ей необходимо получать полную информацию о сессии в каждом запросе. Таким образом, клиент должен отправлять все данные сессии или идентификатор сессии в каждом запросе.
Существует несколько путей реализации этого:
HTML формы
Браузер передает все данные HTML формы при помощи запросов POST или GET. Можно использовать форму, содержащую данные о состоянии, хранимые в скрытых полях формы. Скрытые поля формы нельзя увидеть в браузере, но их можно увидеть в исходном коде HTML. Как правило, данная информация не изменяется и отсылается на сервер с каждым запросом POST или GET. Проблема состоит в том, что опытный пользователь может изменить данные.
HTML ссылки
Также можно создавать ссылки, содержащие идентификатор сессии. Такой идентификатор может быть просто добавлен к запрашиваемому URL при каждом запросе GET. В отличие от HTML форм, такой подход работает с любыми типами ссылок на HTML странице.
Cookies
Другим способом хранения данных о состоянии является cookies, созданные компанией Netscape в 1995 году. Cookies дают серверу возможность хранения информации о сессии на стороне клиента. Сервер хранит небольшие текстовые поля (cookies) в браузере, передавая их в заголовке ответа. Браузер также передает их серверу в заголовке каждого HTTP запроса. Cookie также содержит дополнительную информацию, например, время окончания его действия, информацию о домене и области видимости cookie на веб-сайте и т.д. Браузер обрабатывает эти данные и определяет, какие cookies нужно отправлять с тем или иным запросом. Если клиент получает новый cookie с тем же именем и с того же сервера, происходит обновление старого cookie. Cookies можно использовать для сбора данных о пользователе и для создания подробных профилей пользователя. Например, по информации, взятой из cookies, можно определить сайты, посещаемые пользователем. Но из-за этого cookies часто подвергают критике.
Java-апплет/JavaScript
Сервер может отправить браузеру на выполнение java-апплет или программу JavaScript. Таким образом, эта программа может сохранить данные о сессии и обмениваться этими данными с программой на сервере через POST или GET запросы. Но для этого браузер клиента должен поддерживать Java и JavaScript. Многие пользователи предпочитают не запускать java-апплеты или JavaScript на своих компьютерах, так как это понижает безопасность.
2.6 Динамический контент
Простой веб-сервер предоставляет только статические документы, которые хранятся на сервере в виде файлов. Автор может менять или обновлять эти документы вручную. Вместе с ростом Интернета также выросла потребность в высококачественном мультимедийном контенте - возникла необходимость динамических веб-страниц. Сейчас динамический контент используется повсеместно - от персональных адресных книг до банковских приложений.
В основном веб-клиенты предназначены для отображения страниц, которые они принимают в ответ на запрос. Любой сервер может отправить статичный файл или сгенерированную страницу, основанную на внешнем источнике, например, на базе данных или на данных, полученных от клиента.
Первой технологией, которая позволяла создавать динамический веб-контент, стала CGI. CGI позволяет веб-серверу выполнять внешние программы, которые генерируют HTML код.
Альтернативой стала расширенная функциональность Apache, добавленная специально для выполнения динамических веб-приложений. Для такой возможности к Apache нужно подключить дополнительные модули. Создание отдельного модуля для каждого веб-приложения позволяет достичь хорошей производительности, но такой подход слишком сложен и дорог. Поэтому большинство веб-приложений обычно создаются с помощью языка сценариев, который выполняется интерпретатором, вызываемым через CGI или через модуль интерпретатора.
2.6.1 Серверные сценарии
Самым простым путем, позволяющим серверу предоставлять динамический контент, является использование серверных сценариев. Как упомянуто выше, одной из первых технологий, которая позволяет серверу предоставлять динамический контент, являлась CGI. Для выполнения сценариев, используя CGI, веб-сервер вызывает внешнюю программу. Выполняя этот сценарий, внешняя программа генерирует HTML код, который возвращается серверу. А сервер в свою очередь отправляет этот HTML код клиенту.
Сервер Apache может быть дополнен модулями для поддержки языков сценария, которые будут выполняться при обработке соответствующих запросов. Такой модуль обеспечивает исполнительную среду для сценария и предоставляет API для доступа к внешним источникам данных и данным, полученным от клиента.
В Apache каждый модуль для поддержки какого-либо языка сценария обычно регистрирует отдельный MIME-тип и определяет расширение файлов, которые будут обрабатываться этим модулем.
Обычно серверные сценарии делятся на внедренные в HTML файлы и на сценарии, которые генерируют HTML документ полностью.
HTML файлы со встроенными скриптами
HTML документ может содержать скрипты, которые выполняются на сервере. Обычный HTML документ статичен. Скрипты же заключаются в специальные теги. Сервер обрабатывает эти теги и генерирует HTML код. При помощи серверных скриптов можно обрабатывать данные, полученные из внешних источников (база данных или данные, полученные со стороны клиента).
Серверные включения (SSI)
Одной из таких серверных технологий является технология SSI. Технология SSI позволяет выполнять простые операции (присвоение значения переменной, получение доступа к собственным и системным переменным, простейшие вычислительные операции и даже некоторые системные команды) на сервере, а затем выводить результаты на web-страницу.
SSI позволяет собирать HTML документы из нескольких файлов. Например, для того чтобы упростить программирование динамических страниц, для вывода заголовка и завершения страницы можно использовать SSI.
SSI директивы могут быть записаны в HTML документе при помощи специальных команд, заключенных в теги комментариев. Если сервер не может обработать SSI директиву, браузер ее просто игнорирует:
<!-#ваша_команда ->
Другими серверными языками являются JSP, PHP или ASP.
Скрипты, генерирующие HTML документы полностью
При разработке сложных веб-приложений добавление скриптов в HTML код приводит к снижению скорости загрузки страниц. Поэтому необходимо, чтобы скрипты генерировали HTML документы целиком. Файлы, в которых находятся скрипты, не должны содержать статический HTML код. Это позволит избавить сервер от необходимости разбора документа в поисках скриптов.
Такими скриптами, генерирующими целые HTML документы, являются CGI-программы и Java сервлеты.
Эти технологии являются более мощными и гибкими средствами для динамической генерации HTML кода. Упрощается процесс взаимодействия с внешними приложениями, а также появляется возможность запускать внешние программы в фоновом режиме. Технология CGI используется для запуска внешних программ (например, информация о каталоге - ls -l или dir) и отправки результатов клиенту. Основным недостатком технологии CGI является то, что для каждого запроса порождается новый процесс, что приводит к снижению быстродействия. Также запрещается использовать переменные окружения, такие как STDIN и STDOUT.
Эти недостатки устраняются, если интерпретатор сценария включен в сервер в виде модуля. В этом случае нет необходимости переключать контексты, а взаимодействие сервера и скрипта осуществляется через API сервера и API интерпретатора. Запрос, поступивший на сервер, запускает скрипт и затем возвращает результаты его работы пользователю в виде статичной HTML страницы.
Эффективность и быстродействие программы напрямую зависит от возможностей сервера. Для сложных приложений целесообразно вместо внешнего интерпретатора использовать дополнительные модули, включенные в сервер. Использование API сервера без ограничений, накладываемых на внешний интерпретатор, дает возможность создавать более сложные и мощные приложения.
Продолжение: The Apache Modeling Project. Глава 3 (Часть 1)
 Регистрация доменов
Регистрация доменов
Комментарий от Дмитрий Карпов — Март 24, 2006 @ 11:32 pm
Комментарий от Дмитрий Карпов — Март 24, 2006 @ 11:33 pm
Комментарий от Vika — Май 28, 2006 @ 12:05 pm
Комментарий от Администратор — Май 28, 2006 @ 2:19 pm
Комментарий от Alesha — Май 28, 2006 @ 3:12 pm
Комментарий от Meanser — Май 29, 2006 @ 7:09 pm
Комментарий от Андрей — Июнь 4, 2006 @ 11:05 am
Комментарий от Юра — Июнь 4, 2006 @ 1:58 pm
Комментарий от Bassor — Июнь 16, 2006 @ 11:04 am
Комментарий от Inferka — Июнь 23, 2006 @ 7:35 pm
Комментарий от xz — Декабрь 22, 2006 @ 8:25 am
Спасибо.
Комментарий от Dmitry — Декабрь 24, 2006 @ 10:09 pm
Комментарий от Дёса — Март 22, 2007 @ 2:16 pm
Комментарий от Администратор — Март 22, 2007 @ 2:29 pm
___________________
neopoznannoe.ru/
Комментарий от андрюха — Август 29, 2008 @ 4:28 pm