
The Apache Modeling Project. Глава 2 (Часть 1)
Предыдущая статья: The Apache Modeling Project. Глава 1
2 HTTP серверы
2.1 Введение
Если Вы хотите изучить работу программного продукта, то неплохо бы узнать то, для чего он собственно нужен. Так для сервера необходимо знать о клиентах, ресурсах и протоколах. А так как сервер является только частью системы, то необходимо изучить также и всю систему целиком.
Поэтому сперва мы рассмотрим HTTP сервера и протоколы, такие как HTTP и TCP/IP. Также мы поговорим о динамическом контенте и веб-приложениях.
Раздел 2.2 дает обзор системы, состоящей из HTTP сервера, клиентов и ресурсов. Раздел 2.3 рассматривает протоколы и стандарты, относящиеся к HTTP серверу. Наиболее важный протокол - это HTTP. Остальные разделы описывают другие аспекты системы: идентификация, безопасность и использование протокола HTTP в веб-приложениях. Все эти разделы предоставляют читателю обзорный материал, так как существуют достаточно много других документов, в которых эти аспекты описаны в деталях.
2.2 Задачи HTTP сервера
Основная задача HTTP сервера - это ожидание запросов от клиентов и отправка им ответов. Взаимодействие с клиентами происходит по протоколу HTTP. Клиент (обычно веб-браузер) запрашивает ресурс (обычно HTML файл или графический файл). Сервер связывает запрос с файлом или направляет запрос программе, которая генерирует необходимые данные. После этого сервер отсылает ответ обратно клиенту.
На левой стороне рисунка 2.1 изображена структура очень простой системы: пользователь взаимодействует с браузером, а браузер отсылает запросы HTTP серверу, который, в свою очередь, читает файлы из хранилища (запомните, что сервер имеет доступ только на чтение файлов хранилища).
Это упрощенная структура. Браузер - это программа, запущенная на компьютере пользователя и соединенная по сети с HTTP сервером. Канал между пользователем и браузером подразумевает монитор, мышь и клавиатуру. На данной схеме изображено только одно соединение, хотя браузер может соединиться с множеством серверов одновременно.
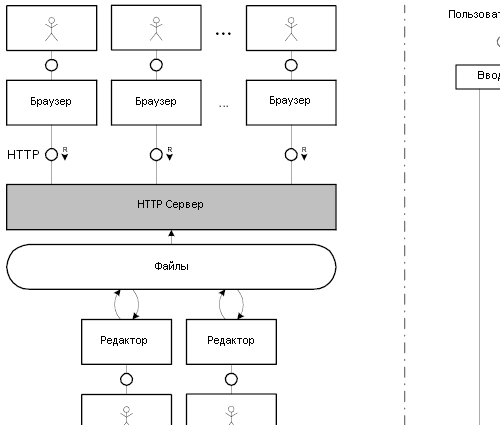
На правой стороне рисунка 2.1 изображено то, что происходит в системе. Сперва пользователь вводит URL в браузере или переходит по гиперссылке. Затем веб-браузер получает адрес сервера из URL и устанавливает с ним TCP/IP соединение. Используя это соединение, браузер отсылает GET запросы HTTP серверу.
HTTP сервер читает запрос и обрабатывает его (определяет имя запрошенного файла). Затем он отсылает запрошенный ресурс, используя установленное соединение, и завершает соединение.
HTML документ может содержать ссылки на другие ресурсы, необходимые для его полного отображения, например изображения или Java-апплеты. Браузер запрашивает их у HTTP сервера так же, как и основной HTML файл. После получения всех ресурсов, необходимых для HTML документа, браузер отображает страницу и начинает ждать дальнейших действий пользователя.
Рисунок 2.1 показывает очень упрощенную модель системы. Понятно, что установка и разрыв TCP/IP соединений для каждого ресурса является пустой тратой времени и трафика. Для предотвращения этого HTTP/1.0 предлагает использовать значение заголовка “Keep-Alive”, а HTTP/1.1 сохраняет соединение с клиентом при его бездействии определенное время (по умолчанию 15 секунд). Мы также упростили поведение браузера - с тех времен, как браузер Netscape заменил Mosaic, он может реагировать на действия пользователей уже при загрузке изображений.
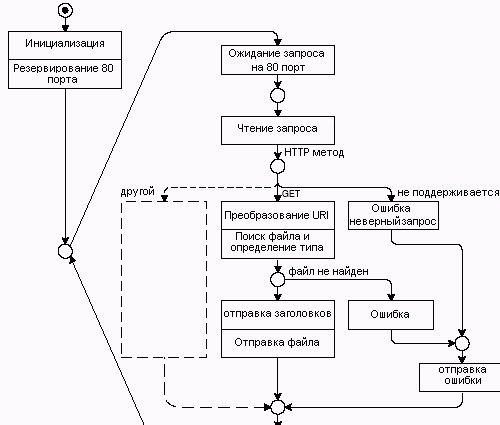
Рисунок 2.2 показывает поведение сервера. После инициализации сервер входит в цикл запрос-ответ. В нем он ожидает входящий запрос, проверяет его, отображает запрошенный ресурс в файл и доставляет его браузеру. После этого он закрывает соединение с клиентом.
Реализовать HTTP сервер, поведение которого изображено на рисунке 2.2 достаточно легко. Он умещается примерно в 100 строках кода. Создать же полноценный HTTP сервер гораздо сложнее по следующим причинам:
Дополнительные возможности
- Полная реализация протокола HTTP (всех версий);
- Обработка конкурирующих запросов (многопроцессность/многонитиевость);
- Предоставление интерфейсов, позволяющих программистам добавлять дополнительные возможности;
- Безопасность (контроль доступа, методы идентификации);
- Динамический веб-контент (CGI скрипты и SSI);
- Виртуальные хосты;
- Функционирование прокси;
- Определение MIME типов ресурсов;
Операции сервера
- Робастность и безопасность операций (24*7);
- Конфигурирование текстовыми файлами;
- Изменение конфигурации без остановки сервера;
- Инструменты администратора для управления сервером;
- Статусная информация сервера;
- Ведение логов;
- Документация для администраторов;
Переносимость и процедура установки
- Одни исходные тексты для разных платформ;
- Простая сборка под специфичные платформы;
- Наличие стандартных конфигураций и полезных шаблонов;
- Документация для разработчиков;
2.3 Протоколы и стандарты
2.3.1 RFC и другие документы
RFC - это серия документов об Интернет, создаваемая с 1969 года. Эти документы описывают множество стандартов, касающихся компьютерных коммуникаций, сетевых протоколов, процедур, программ и концепций. Все стандарты Интернет описаны в RFC.
Чтобы стать стандартом, RFC должна пройти три ступени:
- Предложение стандарта в IESC.
- Черновой стандарт. Он отличается от стандарта лишь в незначительных деталях.
- И если спецификации широко используются и считаются нужными для сообщества, то они получают статус стандарта.
За окончательный вид стандарта отвечает редактор RFC. Функции редактора RFC заключены в организации /go.php?url=http://www.isoc.org.
Для получения дополнительной информации по RFC загляните на сайт /go.php?url=http://www.faqs.org/rfcs. На этом сайте также есть ссылки на все родственные организации, такие как W3C).
2.3.2 TCP/IP
TCP/IP - это самое используемое семейство сетевых протоколов. Его используют все узлы сети Интернет. Стек TCP/IP состоит из 3 основных протоколов: TCP (протокол управления передачей), UDP (протокол пользовательских датаграмм) и IP (межсетевой протокол). Для получения большей информации по протоколам TCP/IP смотрите книгу “Компьютерные Сети” Эндрю Таненбаума, которую можно заказать в Озоне.
TCP и UDP
TCP и UDP для передачи данных используют протокол IP. Протокол IP отвечает за передачу пакетов в место назначения с минимальными затратами, а TCP и UDP используются для подготовки данных к отправке, путем разбиения их на пакеты.
Протокол TCP предоставляет канал для двухстороннего соединения между двумя корреспондентами, используя два потока данных. Перед отправкой или получением данных TCP устанавливает канал с узлом назначения. Чтобы канал мог пропускать два потока данных, TCP разбивает данные на пакеты и следит, чтобы пакеты были доставлены без ошибок и в правильном порядке. Вот почему приложения, использующие TCP, не заботятся о корректности передачи данных. Использование TCP позволяет им оставаться уверенными в том, что данные передадутся успешно и полностью.
UDP является наиболее простым протоколом для передачи пакетов данных. Он просто добавляет заголовок к данным и отсылает их по назначению, не обращая внимания на то, существует ли узел получателя и ожидает ли он данных. UDP не гарантирует, что пакеты будут доставлены в том же порядке, в каком были отправлены. Если пакеты пересылаются между двумя сетями, используя различные пути, то они могут быть доставлены в неправильном порядке. Забота о корректности в этом случае ложится на приложения. Тем не менее, для приложений, которым важна скорость передачи, он полезен, даже несмотря на то, что отдельные пакеты будут потеряны или их порядок будет неправильным. Почти все приложения, использующие видео и голосовые потоки, используют UDP.
Установка TCP соединений
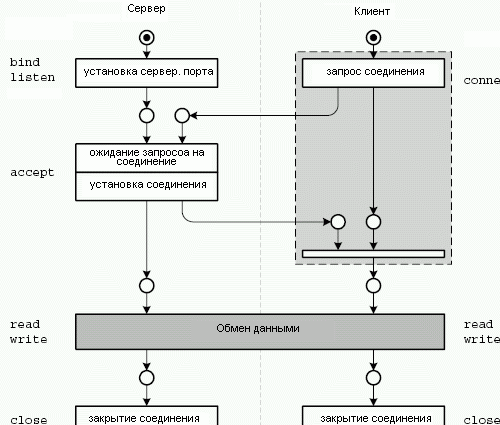
TCP соединение может быть установлено только между двумя узлами: серверный узел ожидает запросы на соединения, а клиентский узел отправляет такие запросы. После получения запроса на соединение, сервер устанавливает соединение. Затем оба узла могут отсылать и получать данные через это соединение. В любое время любой узел (но обычно клиент) может закрыть соединение. Это взаимодействие изображено на рисунке 2.3. На нем также показаны вызовы операционной системы, необходимые для управления сокетами.
Порты
TCP и UDP адрес состоит из IP адреса машины и номера порта. Порты позволяют узлам, использующим протокол TCP/IP, предоставлять несколько веб-сервисов одновременно, а клиентам устанавливать более одного соединения с одним сервером. На сервере порты используются для различия веб-сервисов между собой. HTTP серверы обычно используют хорошо известный порт 80. В любых ситуациях каждое соединение в сети имеет различные пары адресов назначения и источника (IP адреса + номер порта).
IP адреса
IP отвечает за отправку единичных пакетов к месту их назначения. Это достигается путем связывания каждого компьютера в сети с некоторым IP адресом. Каждый IP адрес состоит из 32 бит, представленных в виде четырех десятичных чисел, разделенных точкой, каждое в диапазоне от 0 до 255. Пример IP адреса: 123.123.123.123. Пространство IP адресов разделено на сети, это сделано путем разделения 32 битов адреса на биты сети и биты хоста. Эта информация используется для распределения пакетов по местам назначения.
2.3.3 Система доменных имён (DNS)
Как рассказано в предыдущей части, каждый узел в Интернет может быть идентифицирован с помощью уникального IP адреса. К сожалению, IP адреса - это цифры, которые очень сложно запоминаются.
Пространство имен
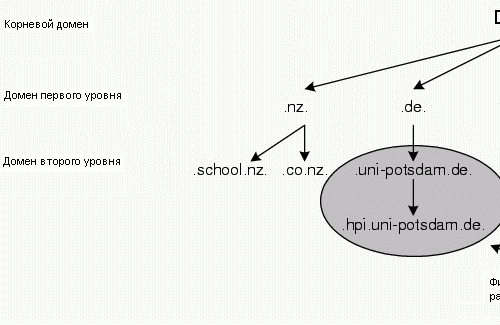
Для решения этой проблемы используется DNS. DNS связывает понятные пользователю имена с IP адресами. Имена, используемые в DNS, организованы в виде иерархического пространства имен. Пространство имен разбито на домены. Наивысший домен - это домен “.” (точка). Домены ниже него приписываются как домены первого уровня, разбивающие пространство имен по странам. Домены первого уровня com, net, org и edu - исключения из этого правила. Первоначально они предназначались только для использования в USA, но сейчас они используются по всему миру. Большинство доменов первого уровня доступны для общего пользования. Человек может зарегистрировать домен второго уровня в пределах почти любого из этих доменов.
Домены первого уровня общего назначения (февраль 2006): .biz .com .info .name .net .org .pro .aero .coop .museum
Иерархия серверов
DNS-сервера организованы иерархически в соответствии со своей зоной ответственности, формируя глобальную распределенную базу данных. Каждый DNS-сервер предназначен для одной или нескольких зон. Каждая зона может содержать одну ветку дерева пространства имен. Сама зона может выделять подзоны для различных серверов имен. Корневой сервер имен отвечает за домен “.” (точка) и выделяет зоны для каждого домена первого уровня. Эти выделенные зоны регистрируются на сервере имен, представляя ее части в качестве доменов второго уровня. Сервер имен конкретной зоны содержит все подзоны и/или имена хостов этой зоны. Рисунок 2.4 показывает зоны и их отношения.
Итеративный и рекурсивный поиск имен
DNS имя может быть запрошено либо с помощью итеративного поиска, либо рекурсивного. Когда используется итеративный поиск, DNS-сервер возвращает либо
- Запрошенный IP адрес;
- Имя DNS-сервера, который может вернуть IP адрес;
- Имя другого сервера имен, который знает, какой сервер ближе к запрошенному имени по дереву пространств имен;
- Или ошибку.
При рекурсивном запросе сервер ищет связанный с именем IP адрес по всем серверам. Если сервер не отвечает за необходимую зону, то он пытается найти нужный сервер, используя итеративные запросы к другим серверам. Сперва он запрашивает корневой сервер на вершине доменного уровня. Затем он отсылает запросы остальным серверам, пока один из них не вернет успешный ответ на запрос. Если ни один сервер не ответил на запрос, тогда последний из них возвращает ошибку, которая обрабатывается клиентом, отправившим рекурсивный запрос. Большинство DNS-серверов, отвечающих за корневую зону или зону первого уровня, могут отвечать только на итеративные запросы. Рисунок 2.4 показывает движение итеративных запросов через иерархию DNS-серверов.
2.3.4 HTTP
HTTP - это основной протокол передачи, используемый в Интернет. Первая, широко применяемая версия HTTP, была версия 1.0. После того, как Интернет стал стремительно развиваться, недостатки первой версии стали очевидными. Протокол HTTP версии 1.1, используемый сегодня, исправил их, а также значительно расширил первую версию. HTTP до сих пор не поддерживает сессии и представляет собой простой протокол запросов - ответов. Для обеспечения надежности, HTTP использует соединения, предоставленные транспортным протоколом TCP/IP. HTTP спроектирован для типичного клиент-серверного поведения.
В HTTP каждый информационный блок адресован с помощью URI (Унифицированный идентификатор ресурсов), который представляет собой адрес, используемый для получения информации. Хотя URI и URL исторически имели различные концепции, сегодня они оба используются для идентификации информационных ресурсов. URL - более широко используемый термин. Пример URL: /index.php. Его результатом будет следующий запрос:
GET /index.php HTTP/1.1
HOST: www.apachedev.ru
HOST: www.apachedev.ru
В этом примере URI имеет значение /index.php
Структура данных HTTP
Передача HTTP данных основана на сообщениях. Запрос, поступивший от клиента, также как и ответ сервера, преобразуется в сообщения. Каждое HTTP сообщение состоит из заголовка и тела сообщения (последнее не обязательно).
HTTP заголовок состоит из 4 частей:
- Запрос/строка статуса (в зависимости от того, запрос это или ответ);
- Главный заголовок;
- Заголовок запроса/ответа;
- Заголовок объекта;
Заголовок и тело HTTP сообщения всегда разделены пустой строкой. Большинство полей заголовка не являются обязательными. Самый простой запрос требует только строку запроса и (с версии HTTP 1.1) поле главного заголовка“HOST” (смотрите раздел 2.3.4). Самый простой ответ сервера содержит только строку состояния.
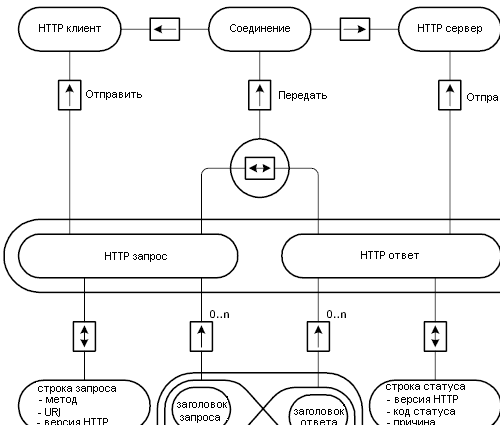
Пример пары сообщений запрос/ответ показаны на рисунке 2.5. E/R диаграммы на рисунках 2.6 и 2.7 показывают структуру HTTP сообщений более подробно.
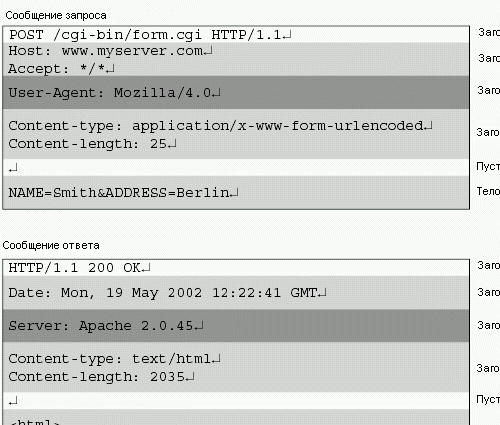
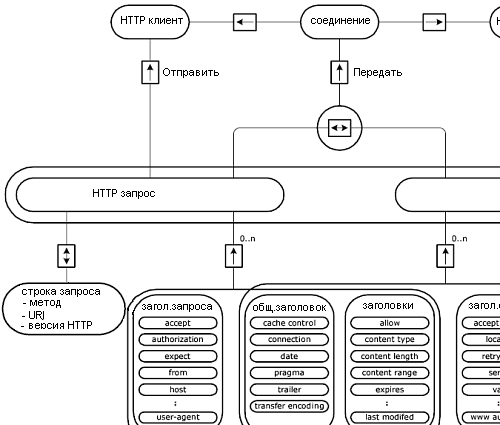
Объясним значения некоторых полей HTTP заголовков. Вот наиболее важные поля заголовков:
- “Content-length” / “Content-type” используются для определения длины и MIME типа тела сообщения. Любой запрос или ответ, обладающий телом, использует эти поля.
- “Referer” используется клиентским приложением для определения родительского документа, использованного для запроса текущего документа. Эти данные могут быть сохранены на сервере для дальнейшего анализа.
HTTP методы
HTTP методы похожи на команды консольного приложения. Ответ сервера определяется HTTP методом, который использовал клиент в своем запросе.
Стандарт HTTP/1.1 определяет следующие методы: GET, POST, OPTIONS, HEAD, TRACE, PUT, DELETE, CONNECT. Наиболее часто используемые методы - это GET и POST.
Метод GET используется для получения запрошенной информации без возможности отправки дополнительных данных в теле самого запроса. Ранее (до HTTP 1.0) GET был единственным методом для запроса информации.
Метод POST похож на метод GET, но POST имеет тело запроса для передачи дополнительных данных серверу. Обычно информация, передаваемая с помощью POST, используется для генерации динамического контента или для сохранения передаваемых данных для других приложений. Метод POST появился в HTTP 1.0.
Для передачи информации серверу методом GET, клиент добавляет ее к URI запроса. Однако это может привести к некоторым проблемам:
- Длина URI может вызвать ошибку обработки на сервере.
- Некоторые клиенты могут передавать URI только определенной длины.
- Большинство клиентов показывают пользователю добавленную к URI информацию.
Хотя метод POST является лучшим способом передачи данных на сервер, некоторые приложения используют для этой цели метод GET, особенно для передачи небольших объемов данных или для возможности добавления закладок на URL.
Все остальные методы используются гораздо реже и будут рассмотрены более кратко:
HEAD. Этот метод запрашивает только заголовки ответа сервера. Он может использоваться, например, когда проверяется существование определенного документа на сервере. Ответ выглядит так же, как если бы Вы запросили его методом GET, но только не содержит тело сообщения.
OPTIONS. Используя этот метод, клиент может запросить список методов и опции сервера для определенного ресурса.
TRACE. Метод TRACE схож с командой Ping в TCP/IP. Сообщение этого запроса обязательно содержит в заголовке поле “Max-Forwards”. Каждый раз, когда это сообщение проходит через прокси-сервер, значение данного поля уменьшается на единицу. Сервер, который получил это сообщение с нулевым значением, отсылает ответ. Если сообщение получает сервер, которому оно адресовалось, то он отсылает ответ, не обращая внимания на значение поля “Max-Forwards”. Используя последовательность таких запросов, клиент может узнать все прокси-сервера, используемые при передаче запрошенного ресурса.
PUT. Используется для передачи серверу файлов. Этот метод схож с командой PUT, используемой в FTP. Использование данного метода несет угрозу безопасности сервера и поэтому почти никогда не используется.
DELETE. Этот метод удаляет на сервере файл, заданный в URI. Так как данный метод также является угрозой безопасности, то ни один из популярных HTTP серверов не обрабатывают его. Метод DELETE очень схож с командой DELETE в FTP.
CONNECT. Эта команда используется для создания безопасного SSL соединения через прокси-сервер. Прокси-сервер должен открыть безопасное соединение с сервером назначения и передать все данные вне зависимости от их содержания.
Ответы сервера
Как рассказано выше, каждый ответ сервера всегда содержит строку статуса. Все ответы сервера разделены на 5 различных категорий. Код ответа - это трехзначное число. Каждая категория обладает уникальной первой цифрой кода:
- 1хх Информационные - Например: 100 Продолжение (100 Continue).
- 2хх Успешные - Например: 200 ОК.
- 3хх Перенаправление - Направляет на другой URL.
- 4хх Ошибка клиента - Например: 404 Не найдено (404 Not found) или 403 Не доступен (403 Forbidden).
- 5хх Ошибка сервера - Например: 500 Внутренняя ошибка сервера (500 Internal Server Error).
Продолжение: The Apache Modeling Project. Глава 2 (Часть 2)
 Регистрация доменов
Регистрация доменов
Комментарий от Василий Свиридов — Апрель 2, 2006 @ 3:42 am
Комментарий от Администратор — Апрель 2, 2006 @ 1:11 pm
Администратор, не убирайте - правильная позиция.
Комментарий от Иван — Июнь 20, 2006 @ 7:23 am
Комментарий от Антон — Сентябрь 2, 2006 @ 2:57 am
Впрочем, если переводчик полагает, что слово “робастность” в данном контексте уместно, может соизволить предоставить широкой общественности его понимание этого, достаточно сложного, термина(неслучайно применяемого только по отношению к статистическим оценкам).
Также, неплохо бы получить смысл фразы : “операция сервера - безопастность”, или “операция- конфигурирование текстовыми файлами”.
По большому счёту, всё что идёт после рисунка 2.2 и до начала раздела 2.3 - какой-то бред из нестыкующихся фраз.
Ещё очень понравилась фраза:”Канал между пользователем и браузером подразумевает монитор, мышь и клавиатуру.”
Комментарий от Сергей — Октябрь 24, 2006 @ 1:36 pm
Комментарий от Петр — Февраль 4, 2007 @ 3:14 pm
Пеши исчо….
Комментарий от rudideath — Июль 29, 2007 @ 3:07 am
Что уж касается заголовков, может кому-то ссылка пригодится:
/go.php?url=/go.php?url=http://www.lib.ru/WEBMASTER/rfc2068/
Комментарий от mak — Октябрь 18, 2007 @ 10:02 pm
__________________________
/go.php?url=/go.php?url=/go.php?url=http://www.vindor.com.ua/
Комментарий от андрюха — Август 29, 2008 @ 4:25 pm